
OCRとは
OCR(光学文字認識(こうがくもじにんしき))とは、写真等から手書き文字を読み取る機能を指します。
Tesseract-OCRとは
Tesseract (テッセラクト)は、色ろなOS上で動作するOCRです。 現在開発は、Googleがやっているみたいですね。 ライセンスはApache License 2.0となりますので、オープンソースみたいですね。 バージョン4以降はニューラルネットワークによるOCRエンジンも組み込まれているので 認識率が向上した見たいです。 無料なのにこの性能で使えるのはなかなかいいですね。 ※詳しくはWikipediaを参照
Tesseract-OCRの導入
Tesseract-OCRのダウンロード
Windowsのインストールファイルのダウンロードはドイツのマンハイム大学図書館提供のインストーラーファイルをダウンロードする事でインストールする事が出来ます。 以下のページにアクセスし自分のOS(32/64bit)に合わせた物をダウンロードします。 name:Home · UB-Mannheim/tesseract Wiki · GitHub 下記が現在(2021/04/05)の最新バージョンのファイルとなります。 ・tesseract-ocr-w32-setup-v5.0.0-alpha.20201127.exe (32 bit) ・tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe (64 bit) ※以降は64bitを元にインストール作業を記載します。
Tesseract-OCRのインストール
ダウンロードした下記のソフトをダブルクリックします。 ・tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe
ダイアログが起動しますので、「Next」をクリックする。
ラインセンス
ライセンス関連の確認なので、問題なければ「I Agree」をクリックする。
インストールユーザの選択
今回は、全ユーザを使用する事を想定しますので 「Install for anyone using this computer」を選択し「Next」をクリックする。
コンポネートの選択
スクリプトの追加 Additional script data(download)の「+」をクリックする。
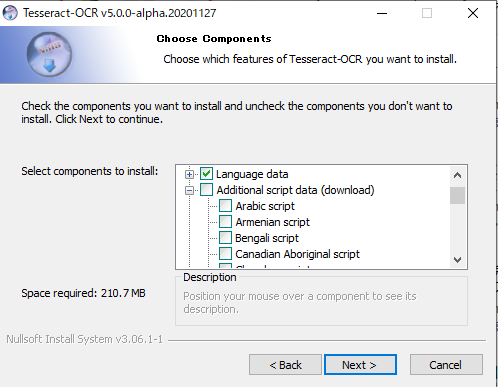
「Japanese script」と「Japanese vertical script」を選択する。
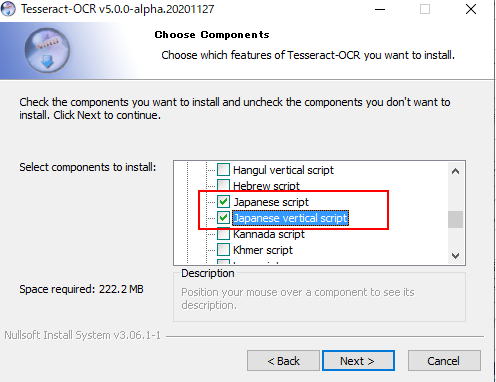
追加の言語データ選択 Additional language data(download)の「+」をクリックする。
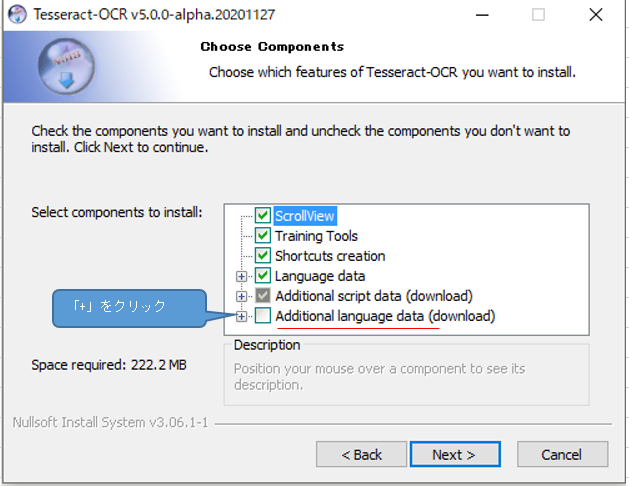
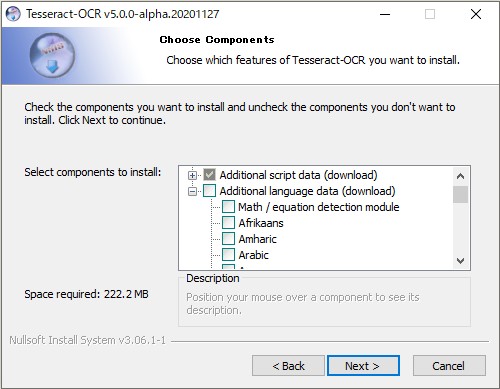
「Japanese 」と「Japanese 」と「Japanese (vertical)」を選択後に「Next」をクリックする。
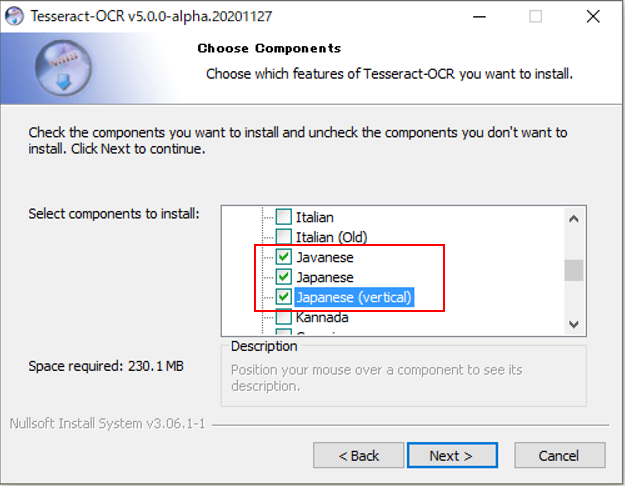
インストール先の選択
通常はディフォルトで大丈夫です。 「Next」をクリックする。
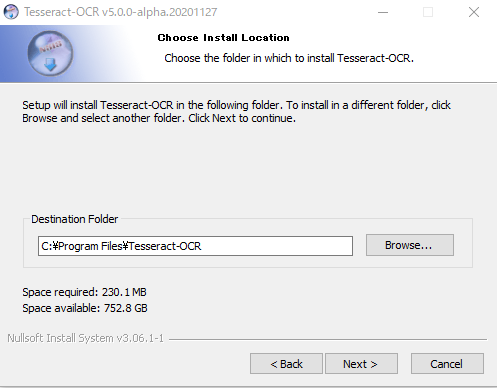
インストールの実行
「Install」をクリックする。
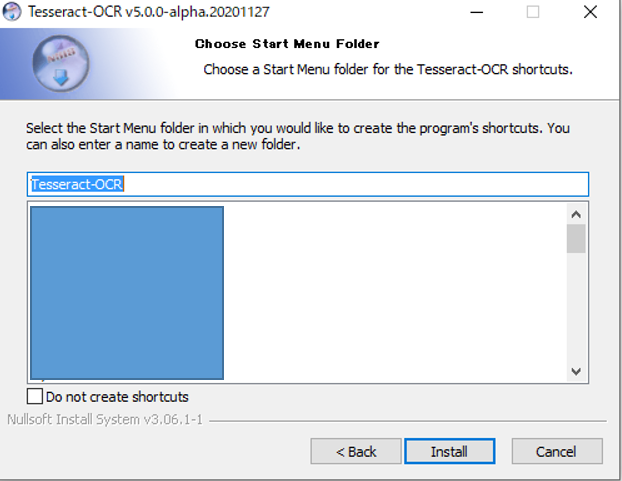
インストール終了したら「Next」をクリックする。
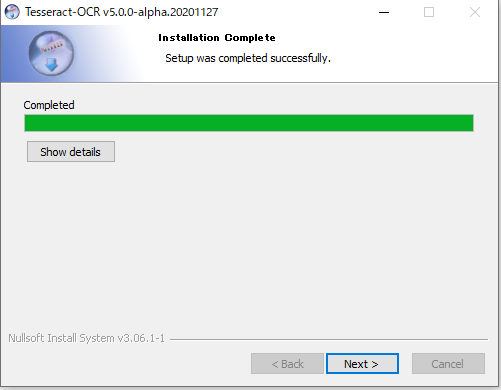
「Finish」をクリックする。 お疲れ様です。 インストールは完了しまいた。
Tesseract-OCRのインストール後の確認
実際に画像から文字を読み取りを試してみます。 下記の画像をサンプルとして使用します。

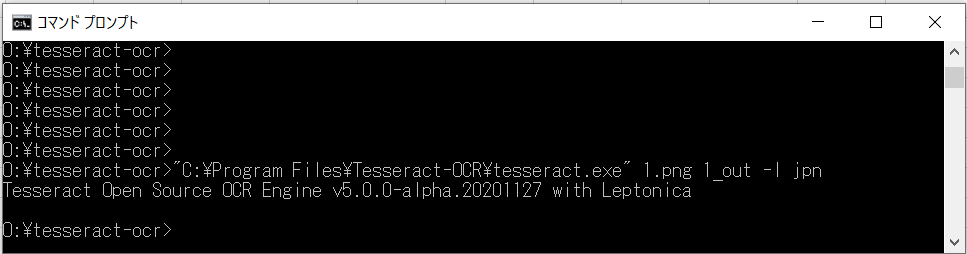
コマンドプロントを起動します。 検索ボックスで「cmd」と入力すると起動できます。 起動後に画像ファイルを配置したフォルダに移動します。 例として、Oドライブに移動します。 「cd /D "O:\フォルダ名"」 ※日本語やフォルダ名にスペースがある場合は「""」でくくります。 下記のコマンドを投入します。 「"C:\Program Files\Tesseract-OCR\tesseract.exe" 1.png 1_out -l jpn」 実行ファイル:"C:\Program Files\Tesseract-OCR\tesseract.exe" 間にスペースがあるので「""」でくくります。 またパスはインストールしたパスを指定します。 INファイル :1.png OUTファイル :1_out オプション : -l jpn ※日本語で認識する
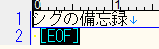
実行後に「1_out.txt」が作成されます。 ファイルを開くと下記の文字が出力されます。


コメント